


Project information
- Aim: Reimplementing the HistoGAN paper
- Outcome: Learning StyleGAN implementation and Histogram processing
- Project URL:
StyleGAN has created huge impact on generative models. It has generated faces that had never existed. The idea of using a style vector was to make generative model insisting on same attribute instances like hair color and nose shape. Moreover, learned style vectors enabled arithmetic operations on attributes such as addition and substraction. That means adding style vector of a person with glasses (remember that the person is also generated) to another generated person without glasses but let's say curly hair generates a person with glasses and having curly hair.
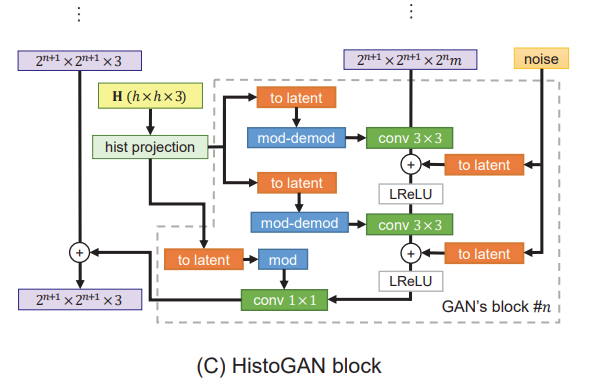
StyleGAN's effect spread across the generative model community. There studied different versions or modifications of StyleGAN. HistoGAN is just one of them. It tries to emphasize the color of generated image. Thus, it modifies generation process of an image with histogram features. The idea is similar to StyleGAN's arithmetic operations. Here, instead of using target generated image as adding style (remember person with glasses example), authors propose using target histogram taken from any target image. Under the hood, briefly, this is handled by adding histogram features to end layers instead of style vector and adding histogram loss to generative loss.
We reimplemented HistoGAN for METU CENG 796 - Deep Generative Models course given by Asst. Prof. Gökberk Cinbiş. The ultimate aim was investigating whether learnign papers are reimplementable along with learning implementation process from scratch. Each group offers a subset of qualitative and quantitative results from paper. We chose Anime dataset from Kaggle and offered subset of it's results. However, we did not fully reach our goals. Our generated images were darker and blurrier. Moreover, they seemed they do not care much about target histogram.
The take home note is generative models are hard to train since they have two parts generative and discriminative. Therefore, it is harder to debug that models. On the other hand, any deep learning project that reach incredible results includes tight finetunings. Moreover, there are lots of parameters and not possible to mention each of them in a paper. Therefore, reimplementing a deep learning paper without knowing the exact parameters can easily go wrong. Disclaimer: this is my opinion.
You can see some generated images from our implementation and expected generations. For further details, please see the git link places at the top of this page.
